Table of Contents
Voice-based Features
We will start with a discussion of useful speech features, and then proceed to some case studies where these features were used to determine contextual information.
Voice Feature: Mel-frequency Spectral Coefficients (MFCC)
As with accelerometer data, the core of a voice-based emotion sensing approach is obtaining good features. Perhaps the most important feature and widely used in voice is Mel-frequency Spectral Coefficients (MFCC).
MFCC is such a useful voice feature that it deserves to be discussed on its own. The MFCC feature (and variants) has been heavily used in speech recognition, for example, it is part of how the Siri software on an iPhone recognizes your command.
What exactly is MFCC and how does it work?
Sounds generated by a human are filtered by the shape of the vocal tract including tongue, teeth etc. This shape determines what sound comes out. If we can determine the shape accurately, this should give us an accurate representation of sound being produced, which in turn can help us design speech processing systems.
The idea in MFCC is to extract features that closest to human perception of voice, since we care about humans interpret speech. The Mel scale relates perceived frequency, or pitch, of a pure tone to its actual measured frequency. Humans are much better at discerning small changes in pitch at low frequencies than they are at high frequencies. Incorporating this scale makes our features match more closely what humans hear.
The MFCC computation pipeline
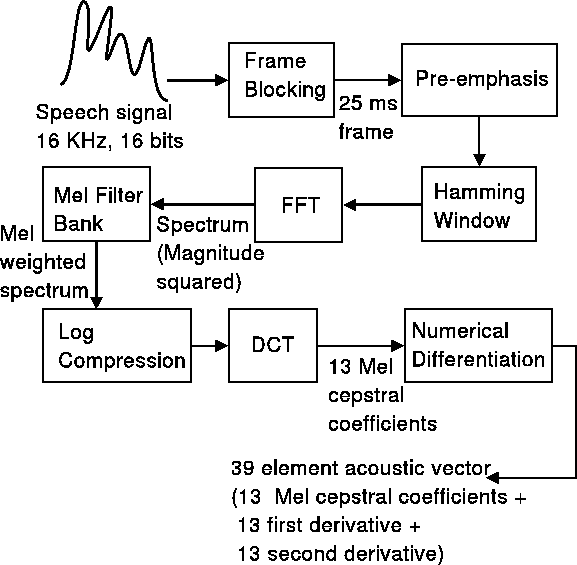
The pipeline by which speech is converted to MFCC features is shown above. The figure looks daunting at first glance, but we will focus on providing you a high-level intuition of how to obtain MFCC features, and how these features work.
Step 1: Windowing. Audio is continuously changing, so we break it down into short segments where we assume that things have been relatively constant. The tradeoff is that if our window is too short, we have too few samples to obtain a consistent result, and if it is too long, we have too many samples to obtain a good result. Typically, voice is broken down into 20-40ms segments.
Step 2: Power spectrum. The next step is to calculate the power spectrum of each frame. This is motivated by the human cochlea (an organ in the ear) which vibrates at different spots depending on the frequency of the incoming sounds. Depending on the location in the cochlea that vibrates (which wobbles small hairs), different nerves fire informing the brain that certain frequencies are present. Our periodogram estimate performs a similar job for us, identifying which frequencies are present in the frame.
Step 3. Apply Mel Filterbank. The periodogram spectral estimate still contains a lot of information that is unnecessary for speech recognition. In particular the cochlea can not discern the difference between two closely spaced frequencies. This effect becomes more pronounced as the frequencies increase. So, this step is just a way to combine the frequency spectrum into bins that is similar to how our ear perceives voice. The first filter is very narrow and gives an indication of how much energy exists near 0 Hertz where human hearing is very sensitive to variations. As the frequencies get higher our filters get wider as we become less concerned about variations.
The formula for converting from frequency to Mel scale is:
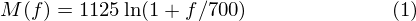
To go from Mels back to frequency:
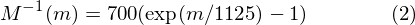
Step 4. Logarithm of the Mel filterbank. Once we have the filterbank energies, we take the logarithm of them. This is also motivated by human hearing: we don’t hear loudness on a linear scale. Generally to double the percieved volume of a sound we need to put 8 times as much energy into it. This means that large variations in energy may not sound all that different if the sound is loud to begin with. This compression operation makes our features match more closely what humans actually hear.
Step 5. DCT of the log filterbank. The final step is to compute the DCT of the log filterbank energies. This step is a bit harder to understand without a signal processing background. Intuitively, the idea is that there are a lot of correlations between the log filterbank energies, and this step tries to extract the most useful and independent features.
At the end of the DCT, you get 13 MFCC coefficients; typically, these are combined with a few other features extracted through the same pipeline such as first derivative and second derivative coefficients. We won’t discuss them in detail here. Together, you get a 39 element acoustic vector that are the core features used in speech processing algorithms.
Other Audio Features
While MFCC are a very useful feature, this by no means the only one. In fact, there are many other features that are particularly useful in understanding emotional content of speech. Emotional speech processing tries to recognize the user’s emotional state by analyzing speech patterns.
You might wonder how features that capture emotion differ from those described above and used in speech processing. The distinction is that when we discussed MFCC and related features, we wanted to capture the content of sound, whereas with emotion processing, we want to capture the sound characteristics a.k.a. prosody. An intuitive distinction is that the content is about the words in speech, i.e., what we are saying, whereas the prosody is about the sound characteristics of speech, i.e., how we say it. In terms of acoustics, the prosodics of oral languages involve variation in syllable length, loudness, pitch, and the formant frequencies of speech sounds. We discuss some of these features below.
- Pitch: Pitch describes how a listener perceive a sound. A sudden increase in pitch can often be perceived as high activation, such as anger, whereas low variance of pitch is often conceived as low energy, for example, sadness.
- Intensity: The intensity reflects the effort to produce speech. Studies showed that angry utterance usually displays rapid rise of energy, and on the contrary sad speech usually is characterized by low intensity. Based on the observation, we need features that can describe the overall energy level and some momentary energy
onset' andoffset’. - Temporal Aspects: In temporal aspects are measures that can describe speech rate and voice activity (i.e., pauses). Some research showed that those two temporal properties may be affected by emotions. For example, sadness often result in slower speech and more pauses.
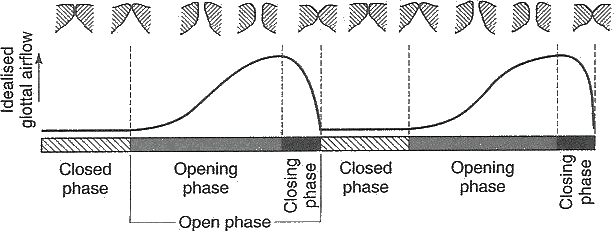
- Voice Quality: Emotions may also influence the voice quality of utterances. For example, some voice becomes sharp or jagged while some voice sounds soft. Glottal waveforms are useful to describe these sound characteristics. As illustrated in the above figure, a glottal (flow) waveform represents the time that the glottis is open (with air flowing between vocal folds), and the time the glottis is closed for each vibrational cycle. In addition, an open phase can be further broken down into opening and closing phases. If there is a sudden change in air flow (i.e., shorter open and close phases), it would produce more high frequency and the voice therefore sounds more jagged, other than soft. To capture it, we need features that describe timings of the phases and the ratios of closing to opening phase, open phase to total cycle, closed phase to total cycle, opening to open phase, and closing to open phase.
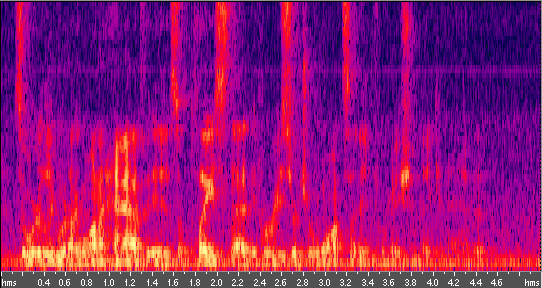
- Spectrogram: A spectrogram can describe the energy distribution across frequency bands (as shown above). The reason was that the emphasis on certain frequency may be speaker dependent and may be used to reflect emotions.
- Other Statistical Measures: There are several basic statistical measures, which can help represent all possible dynamics which might be affected by emotions.
References
[1] Speech Emotion Classification using Machine Learning Algorithms, S. Casale, A. Russo, G. Scebba
[3] OpenEAR - Introducing the Munich Open-Source Emotion and Affect Recognition Toolkit, Florian Eyben, Martin Wollmer, and Bj ¨ orn Schuller
[4] StressSense: Detecting stress in unconstrained acoustic environments using smartphones, Lu, H., Frauendorfer, D., Rabbi, M., Mast, M. S., Chittaranjan, G. T., Campbell, A. T., … & Choudhury, T.