Table of Contents
Classification of Health State
Voice is an extremely useful and important part of health analytics. There are many interesting questions that can be answered with audio processing – for example, how much social interaction does a person engage in? what is the emotional content of the voice? and so on. These indicators can be leveraged for understanding depression, stress, mood, and many other factors that are relevant to personal health. We will now look at some interesting ways in which voice processing can be used for obtaining measures of health.
Voice Analysis Library: Classification
We’re now going to look at how the different features listed above can be used in a variety of classification tasks. Audio classification is a vast field, and a detailed description of the technique will require both substantial time and significant mathematical maturity. So, we stay at a more superficial level, and try to provide you an idea of the techniques so that you can explore on your own if you are interested. We start with speech processing (e.g. Siri), and then discuss one example of an emotion recognition system.
Speech processing
Speech processing is a field that has seen a huge amount of work. There are complex models, and complex algorithms underlying them that are out of scope for this class. Our goal here is only to introduce the ideas so that you are familiar with how a basic speech processing system can be constructed.
Human speech can be broken into phonemes – for example, when you look up a word in a dictionary, you get the phonetic pronunciation of the word, which is a combination of phonemes. An example of a phoneme in English is /k/, which occurs in words such as cat, kit, school, skill, kite.
The challenge in speech recognition is to recognize a sequence of phonemes as a particular word. In the example above, lets say a word starts with the phoneme /k/ (assume for the moment that we can identify start of words). There are a huge number of words that start with the phoneme /k/, so how does the system identify which is the word being spoken?
To do this, speech recognizers use temporal models such as a Hidden Markov Model (HMM). At a high level, a HMM for each letter in the alphabet tries to look for a sequence of phonemes, while taking into account the fact that different people pronounce letters differently (therein the distribution shown below each circle in the figure below).
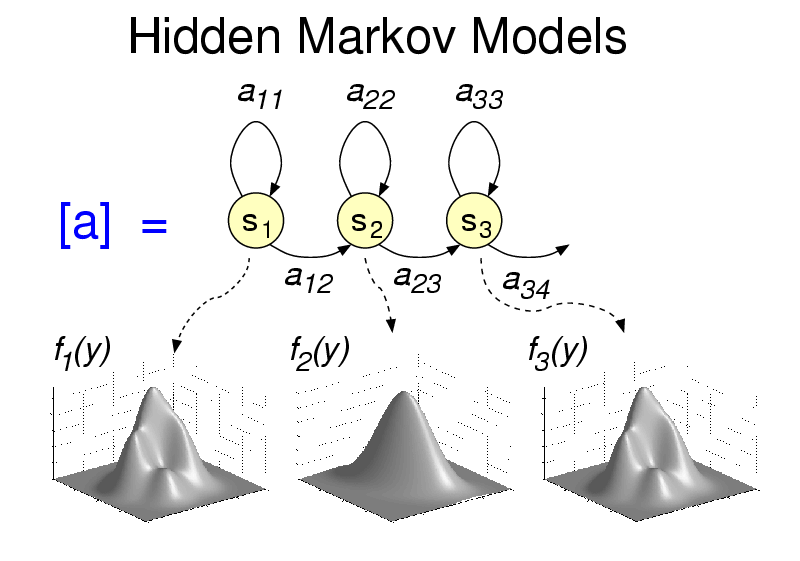
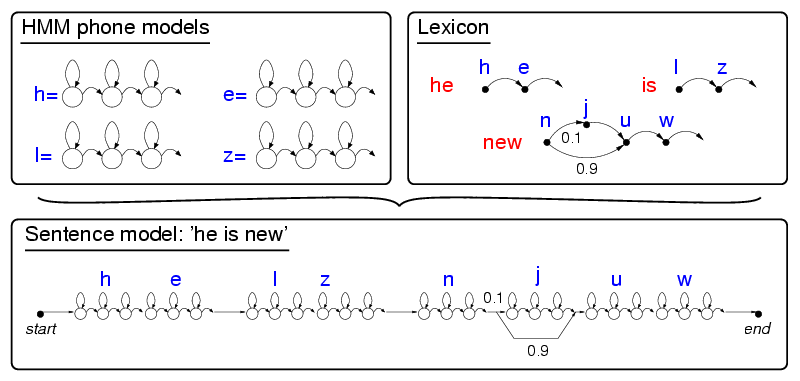
Hidden Markov Models are extremely powerful, and can be composed to identify letters, then words, and then sentences as shown below.
As described earlier, the most useful feature for speech recognition is the acoustic feature vector (MFCC + others). These are the core features that are used to distinguish between different phonemes, and thereby the different letters, words, sentences, etc.
Diagnosis of Mental Illnesses
Mental illness such as depression are well known to have substantial effect on voice. Table 1 shows the aspects of speech that mental health practitioners pay particular attention to when performing a mental state examination of patients. These parameters help describe a patient’s current state of mind, under the domains of appearance, attitude, behavior, mood and affect, speech, thought process, thought content, perception, cognition, insight and judgment. For example, depressed patients often express slow responses (longer response time to questions and pause time within sentences), monotonic phrases (less fundamental frequency variability), and poor articulation (slower rate of diphthong production). On the other hand, the spectrum of agitated behavior includes expansive gesturing, pacing and hair twirling. As can be seen, many of the prosodic features capture these variations; in addition, speech related features such as MFCC capture speech intensity.
| Category | Patterns |
| Rate of speech | slow, rapid |
| Flow of speech | hesitant, long pauses, stuttering |
| Intensity of speech | loud, soft |
| Clarity | clear, slurred |
| Liveliness | pressured, monotonous, explosive |
| Quality | verbose, scant |
Table 1: Speech Descriptors in Mental Status Exam
Monitoring Affect with a Mobile Phone
There are many interesting applications for affect/mental health monitoring by voice. Consider the following examples:

Cell-phone monitoring of healthy subjects as part of a health-care package. Using voice analysis algorithms on the phone itself, the voice is analyzed during cell phone conversations. Subjects are directly informed if problems are detected by the voice analysis software. In the early stages, they are likely to seek treatment in many cases. Rather than individual sign-up, this would be part of a health “package” from a provider which includes physical health as well.
Subsidized “calling-card” number for at-risk populations. Subjects can make free calls on a normal phone using a special access number. This number routes calls through a cloud of servers where voice is analyzed. Distinct access codes would allow per-patient tracking. This method should be cost effective for many chronic conditions such as AIDS where mentally ill patients add severe cost overhead due to wasted (not taken) medication and (corollary) drug-resistance strains of the virus.
Monitoring of human-computer speech interfaces and interpersonal speech for elders in assisted or independent care. Environmental monitors (array microphones that work 10-20 feet from subjects) can be used to gather incidental speech between subjects. For subjects living alone, speech interfaces may be introduced as a convenient way for subjects to access email, text messages, news, weather and personal schedule information. These routine services provide regular opportunities to intercept and analyze their speech for mental health purposes.
Monitoring our stress in everyday lives. Microphones, embedded in mobile phones and carried ubiquitously by people, provide the opportunity to continuously and non-invasively monitor stress in real-life situations using an approach very similar to that for identifying depression. Everyone experiences stressful situations, either because of work pressures, exams, personal circumstances, or others. Maybe your phone can inform you that you should do something about your stress levels, perhaps play calming music, or take a break.
Monitoring Social Interactions (or lack of it). Your phone can recognize when there is conversation in the vicinity (using speech-based features), and also whether you are speaking or someone else (since individuals have distinctive speech patterns). Using this information, your phone may be able to monitor your daily social interactions, and identify whether you have gone long periods without contact with someone (a common problem in the digital age). Maybe it can give you notifications that its time to get off your computer and socialize!
Conclusion
Speech and sound is extremely important in our lives, and an amazing amount of information can be gleaned from recorded audio from a simple microphone. As microphones become more powerful and more ubiquitous, the possibility that computing systems will be able to monitor 24/7 and identify changes in health patterns has exciting possibilities for understanding ourselves and in anticipating problems. But it also presents many roadblocks, not just in the audio data analysis, but also in making sure people’s privacy is not violated in the process.
References
[1] Speech Emotion Classification using Machine Learning Algorithms, S. Casale, A. Russo, G. Scebba
[2] Speech Analysis Methodologies towards Unobtrusive Mental Health Monitoring, Keng-hao Chang
[3] OpenEAR - Introducing the Munich Open-Source Emotion and Affect Recognition Toolkit, Florian Eyben, Martin Wollmer, and Bj ¨ orn Schuller
[4] StressSense: Detecting stress in unconstrained acoustic environments using smartphones, Lu, H., Frauendorfer, D., Rabbi, M., Mast, M. S., Chittaranjan, G. T., Campbell, A. T., … & Choudhury, T.